Echelon : Turning Stranded Enterprise GPUs Into a Private AI Cloud
How Echelon turns heterogeneous, access-controlled devices into an auditable AI training fabric

The first era of AI infrastructure was built around a clean assumption: put homogeneous accelerators in one place, connect them with fast links, centralize the data, and scale the model from there.
That recipe worked for frontier labs. It does not match how most enterprises actually operate.
A hospital does not have one flat data lake. A bank does not have one unrestricted trust domain. A manufacturing company does not have all of its useful compute sitting in one uniform GPU cluster. A university lab may have a few new accelerators, several older GPUs, shared workstations, edge machines, and strict rules about which data can leave which environment.
This creates a strange paradox: many organizations already own useful compute, but cannot use it as a single AI cluster.
Some of the compute is underutilized. Some of the data cannot move. Some devices are fast, some are weak, some are on slow links, and some are only allowed to see specific classes of data. The result is that model development remains bottlenecked on expensive centralized cloud GPUs, even when useful capacity is already scattered throughout the organization.
Echelon is our answer to that problem. Echelon is a private AI compute fabric for heterogeneous enterprise clusters. It is designed around two ideas:
1. The topology plane:
Decide where computation should run.
2. The boundary plane:
Decide what information is allowed to move.
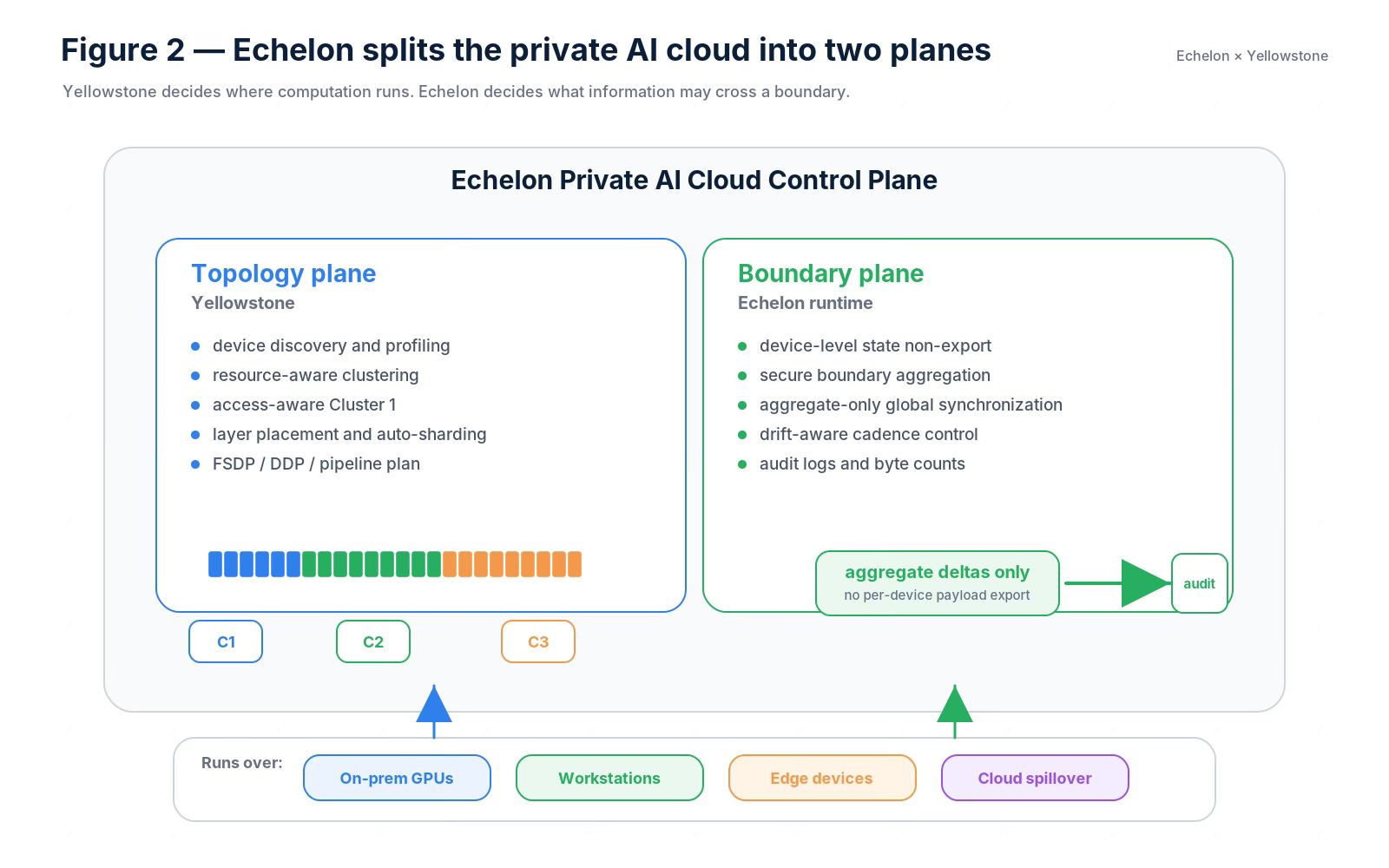
The boundary plane is Echelon’s privacy and audit layer. It enforces a hard information-flow rule: device-level parameters, activations, optimizer state, and per-device updates do not cross administrative boundaries. The global plane receives only securely aggregated boundary-level deltas and bounded coordination metadata. This turns privacy from an overlay into a systems invariant.
The topology plane is Yellowstone, the auto-sharding and placement engine inside Echelon. Yellowstone profiles available devices, understands access tiers, forms resource-aware clusters, shards model layers across those clusters, and composes the right parallelism strategy for the available hardware: FSDP inside clusters, DDP where data differs, and pipeline parallelism across clusters.
In short:
Echelon makes private training auditable. Yellowstone makes heterogeneous training schedulable.
Together, they point toward a different kind of AI cloud: not a place where every organization must move all data and compute, but a control plane that makes the hardware an enterprise already owns behave like a governed training substrate.
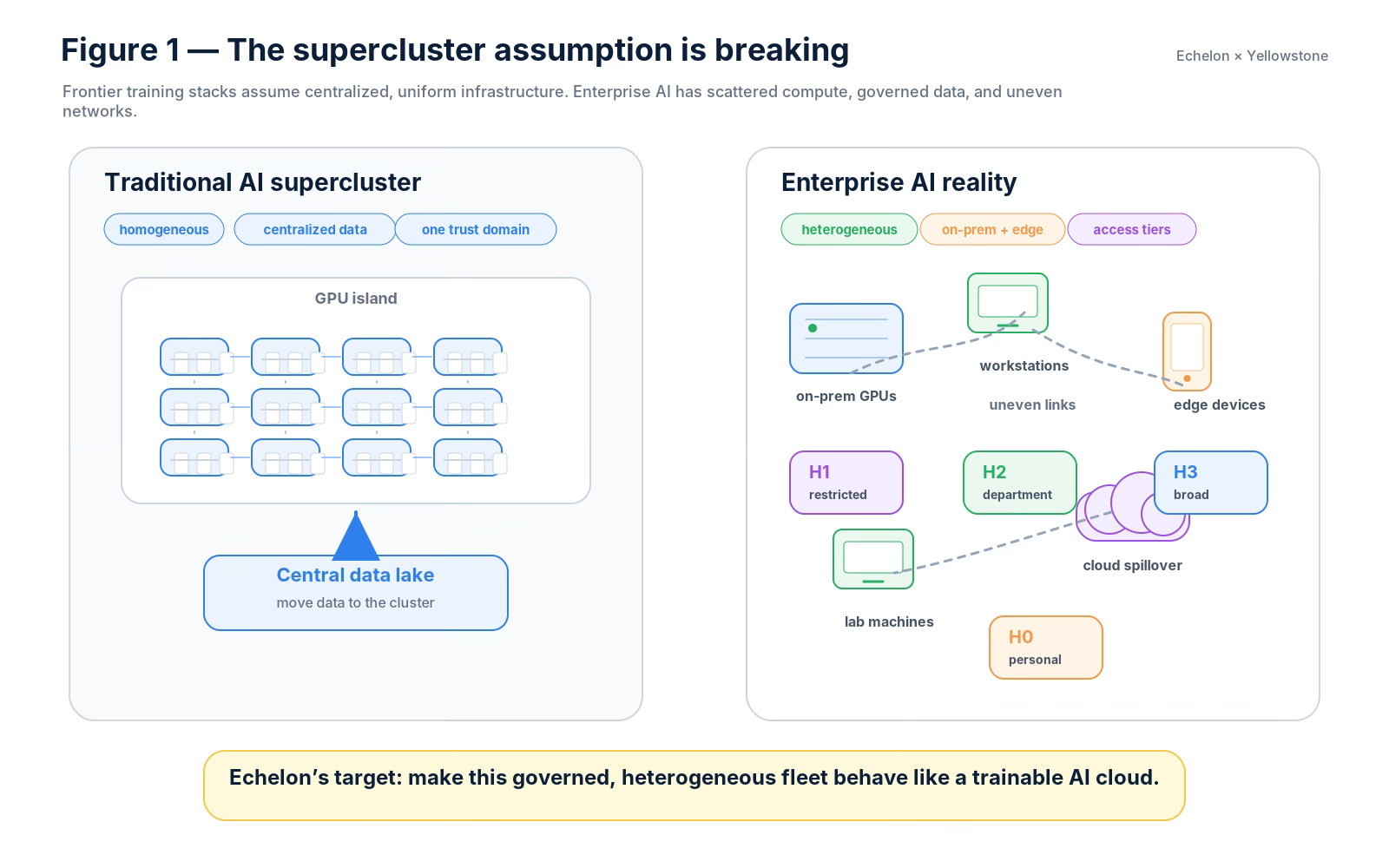
The supercluster assumption is breaking
Most large-model infrastructure still assumes a world like this: Homogeneous GPUs, Fast interconnect , Centralized data, One trust domain, One administrator and One billing boundary
But enterprise AI usually looks more like this: Mixed GPUs, CPUs, and edge devices, Uneven bandwidth and latency, On-prem and cloud environments, Department-owned machines, Regional and regulatory data boundaries, Role-based access tiers with Idle or underutilized accelerators
Traditional distributed training systems are very good when the first world exists. They are less natural in the second world.
Federated learning handles decentralized data better, but often assumes each participant can hold a full model or participate in relatively simple update protocols. Model-parallel systems such as ZeRO, Megatron-style tensor parallelism, and FSDP-style sharding make large models trainable, but they are typically designed for tightly controlled clusters where model state can move freely between nodes.
Echelon starts from a different premise:
The next enterprise AI cloud will be heterogeneous by default.
That means the scheduler cannot optimize only for FLOPs. It has to reason about memory, network cost, latency, access policy, privacy boundaries, and model placement at the same time.
A device should not receive a model slice simply because it is fast. It should receive that slice only if it can run it, communicate efficiently with its neighbors, and satisfy the organization’s access policy.
That is the core problem Yellowstone solves.
The product thesis: use the cluster you have
The cheapest GPU is often the one an organization already owns but cannot use effectively.
Enterprises have stranded AI capacity everywhere: developer workstations, department GPU boxes, aging on-prem accelerators, regional cloud accounts, lab machines, and edge devices close to private data. The hard part is not merely discovering those devices. The hard part is turning them into a safe, useful training topology.
That requires a control plane with three jobs:
Discover:
What devices exist?
What memory, compute, bandwidth, and reliability do they have?
Plan:
Which devices should work together?
Which model layers should run where?
Which parallelism strategy should be used at each level?
Govern:
Which data and model artifacts are allowed to move?
What can cross a boundary?
What must remain local?
What can an auditor verify?
Echelon’s view is that AI infrastructure should not force every organization into the same centralized cloud pattern. Instead, the cloud should become a control plane over heterogeneous private compute.
That does not mean public cloud disappears. It means public cloud becomes one tier in a larger fabric: a spillover resource, a burst pool, or a high-end accelerator island, rather than the default location where all data and training must happen.
Echelon: the boundary-aware runtime
Echelon begins with the governance problem.
In many real deployments, the question is not simply “how do we optimize the model?” The question is:
How do we optimize the model while making the allowed information flow explicit, enforceable, and auditable?
Echelon organizes training into three planes:
Device plane:
Devices train locally inside a boundary.
Boundary plane:
A boundary aggregates local updates using buffering,
staleness-aware weighting, participation windows,
clipping, and secure aggregation.
Global plane:
The global coordinator receives only aggregate boundary-level deltas
and bounded coordination metadata.
The important design choice is that the global plane does not see per-device state. Per-device parameters, activations, optimizer state, and per-device update vectors stay inside the boundary. Only boundary-level securely aggregated deltas cross.
This is different from saying, vaguely, “the system is privacy-preserving.” Echelon’s contract is operational. It defines what message types are allowed, what message types are forbidden, and what an audit should inspect.
That matters because enterprise privacy is not only a mathematical question. It is also an operational question. Can a compliance team inspect logs? Can an auditor check schemas? Can the system prove that the global coordinator did not receive per-device payloads?
In the current Echelon paper, the audit trace reports zero per-device payload bytes across loopback, emulated WAN, and real cross-region deployments.
This gives Echelon its boundary plane.
But once the boundary contract is fixed, a second problem appears.
If only certain information can move, and only certain devices can see certain data, then training placement becomes much harder.
That is where Yellowstone comes in.
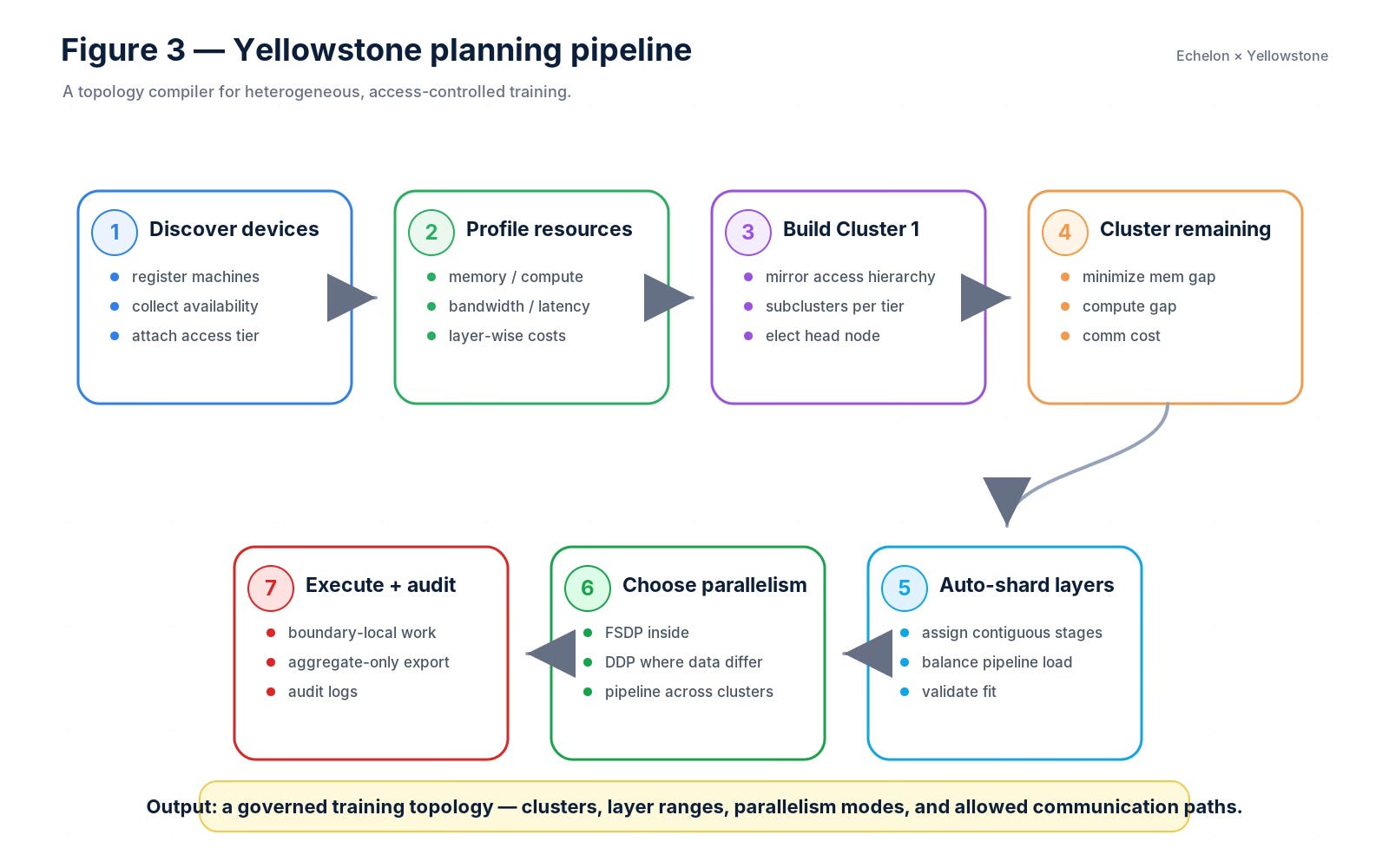
Yellowstone: the topology compiler
Yellowstone is the topology compiler inside Echelon.
It takes a messy enterprise fleet and emits a training topology.
Input:
Devices
Memory profiles
Compute profiles
Bandwidth and latency
Access tiers
Model layer costs
Boundary constraints
Output:
Device clusters
Layer-to-cluster placement
Parallelism strategy
Head-node assignments
Backup / fault-tolerance plan
Boundary-compatible execution graphThe goal is to turn this:
18 uneven devices
3 access tiers
2 slow links
4 high-memory GPUs
8 midrange GPUs
6 weak or edge devices
one model too large for any single deviceinto this:
Cluster 1:
access-aware input / representation stage
Cluster 2:
layers 0–9 on high-memory devices
Cluster 3:
layers 10–23 on midrange devices
Cluster 4:
layers 24–31 on lower-memory devices
Across clusters:
pipeline parallelism
Inside clusters:
FSDP or data parallel execution
Across privacy boundaries:
Echelon aggregate-only synchronizationYellowstone’s core idea is simple but powerful:
Do not assume the cluster is homogeneous. Compile the training plan around the hardware and policies that actually exist.
The Yellowstone design starts with device and model profiling, forms an access-aware first cluster, dynamically clusters remaining devices using memory/compute/communication cost, partitions layers by fractional resource budgets, and then uses FSDP, DDP, and pipeline parallelism at different levels of the topology.
This makes Yellowstone more than a scheduler. It is a resource-aware compiler for distributed training graphs.
Why this can be cheaper
The main cost advantage is not magical compression. It is better utilization of existing assets.
Echelon can lower the barrier to enterprise AI because it lets organizations:
use idle or stranded compute they already own;
avoid unnecessary data movement;
keep sensitive data close to its source;
reserve expensive cloud accelerators for spillover;
reduce manual engineering needed to hand-place model shards;
audit cross-boundary traffic instead of trusting informal process.In many organizations, the cost of AI is not just GPU rental. It is also data movement, compliance friction, duplicated infrastructure, underutilized on-prem machines, and engineering time spent trying to make non-uniform hardware behave like a cluster.
Yellowstone attacks the utilization problem. Echelon attacks the governance problem.
Together, they turn scattered machines into a private AI cloud.
We would love to hear your thoughts on this, you can email me at hina@decompute.run.